
13장 동시성
객체는 처리의 추상화다. 스레드는 일정의 추상화다.
동시성과 깔끔한 코드는 양립하기 어렵다.
여러 스레드를 동시에 돌리는 이유와 여러 스레드를 동시에 돌리는 어려움에 대한 대처 방법과 깨끗한 코드를 작성하는 방법을 알려주는 챕터.
동시성을 테스트하는 방법과 동시성의 문제점을 이야기한다.
깨끗한 동시성은 복잡한 주제로 이 챕터에서는 간략히 소개만 하는 것이다.
목차
- 동시성이 필요한 이유?
- 미신과 오해
- 난관
- 동시성 방어 원칙
- 단일 책임 원칙
- 따름 정리: 자료 범위를 제한하라
- 따름 정리: 자료 사본을 사용하라
- 따름 정리: 스레드는 가능한 독립적으로 구현하라
- 라이브러리를 이해하라
- 스레드 환경에 안전한 컬렉션
- 실행 모델을 이해하라
- 생산자-소비자
- 읽기-쓰기
- 식사하는 철학자들
- 동기화하는 메서드 사이에 존재하는 의존성을 이해하라
- 동기화하는 부분을 작게 만들어라
- 올바른 종료 코드는 구현하기 어렵다
- 스레드 코드 테스트하기
- 말이 안 되는 실패는 잠정적인 스레드 문제로 취급하라
- 다중 스레드를 교려하지 않은 순차 코드부터 제대로 돌게 만들자
- 다중 스레드를 쓰는 코드 부분을 다양한 환경에 쉽게 끼워 넣을 수 있게 스레드 코드를 구현하라
- 다중 스레드를 쓰는 코드 부분을 상황에 맞게 조율할 수 있게 작성하라
- 프로세서 수보다 많은 스레드를 돌려보라
- 다른 플랫폼에서 돌려보라
- 코드에 보조 코드를 넣어 돌려라. 강제로 실패를 일으키게 해보라
- 직접 구현하기
- 자동화
13-1. 동시성이 필요한 이유?
동시성은 결합(coupling)을 없애는 전략이다.
다시말해 무엇(what)과 언제(when)를 분리하는 전략이다.
무엇과 언제를 분리하면 애플리케이션 구조와 효율이 극적으로 나아진다.
구조적인 관점에서 프로그램은 거대한 루프 하나가 아니라 작은 협력 프로그램 여럿으로 보인다.
응답 시간과 작업 처리량(throughput)을 개선하려면 직접적인 동시성 구현이 불가피하다.
그래서 반드시 동시성이 필요한 상황이 존재한다.
13-1-1. 미신과 오해
동시성은 항상 성능을 높여준다.
동시성은 때로 성능을 높여준다.
대기 시간이 아주 길어 여러 스레드가 프로세서를 공유할 수 있거나,
여러 프로세서가 동시에 처리할 독립적인 계산이 충분히 많은 경우에만 성능이 높아진다.
동시성을 구현해도 설계는 변하지 않는다.
단일 스레드 시스템과 다중 스레드 시스템은 설계가 판이하게 다르다.
일반적으로 무엇과 언제를 분리하면 시스템 구조가 크게 달라진다.
웹 또는 EJB 컨테이너를 사용하면 동시성을 이해할 필요가 없다.
컨테이너가 어떻게 동작하는지 어떻게 동시에 수정하고 데드락 등과 같은 문제를 피할 수 있는지 알아야 한다.
13-1-2. 동시성에 대한 타당한 생각
동시성은 다소 부하를 유발한다.
성능 측면에서 부하가 걸리며 코드도 더 길어진다.
동시성은 복잡하다.
간단한 문제라도 동시성은 복잡하다.
일반적으로 동시성 버그는 재현하기 어렵다.
진짜 결함으로 간주되지 않고 일회성 문제로 여겨 무시하기 쉽다.
동시성을 구현하려면 근본적인 설계 전략을 재고해야 한다.
13-2. 난관
동시성을 구현하기가 어려운 이유는 무엇일까?
public class X {
private int lastIdused;
public int getNextId(){
return ++lastIdused;
}
}인스턴스 X를 생성하고, lastIdused를 42로 설정한 다음 두 스레드가 해당 인스턴스를 공유할 때
두 스레드가 getNextId()를 호출한다면 결과는 셋 중 하나다.
하나의 스레드는 43을 받고 다른 스레드는 44를 받는다.
하나의 스레드는 44을 받고 다른 스레드는 43를 받는다.
하나의 스레드는 43을 받고 다른 스레드는 43를 받는다.
lastIdused는 44를 넘어가지 못한다.
객체 하나를 공유한 후 동일 필드를 수정하던 두 스레드가 서로 간섭하므로 예상하지 못한 결과를 내놓게 된다.
13-3. 동시성 방어 원칙
동시성 코드가 일으키는 문제로부터 시스템을 방어하는 원칙과 기술
13-3-1. SRP
동시성 코드는 다른 코드와 분리해야 한다.
동시성 코드는 독자적인 개발, 변경, 조율 주기가 존재한다.
동시성 코드에는 독자적인 난관이 있다.
다른코드에서 겪는 난관과 다르며 훨씬 어렵다.
잘못 구현한 동시성 코드는 별의별 방식으로 실패한다.
13-3-2. 따름 정리: 자료 범위를 제한하라.
자료를 캡슐화 하라, 공유 자료를 최대한 줄여라.
공유 객체를 사용하는 코드 내 임계영역(critical section)을 synchronized 키워드로 보호하라.
critical section의 수를 줄이는 기술이 중요하다.
공유자료를 수정하는 위치가 많을수록 보호할 critical section을 빼먹게 된다.
그래서 공유 자료를 수정하는 모든 코드를 망가뜨린다.
모든 critical section을 올바로 보호했는지 확인하느라 똑같은 수고를 반복한다.
찾아내기 어려운 버그가 더욱 찾기 어려워진다.
13-3-3. 자료 사본을 사용하라
공유 자료를 줄이려면 처음부터 공유하지 않는 방법이 제일 좋다.
객체를 복사해 읽기 전용으로 사용하거나 각 스레드가 객체를 복사해 사용한 후 한 스레드가 해당 사본에서 결과를 가져오는 방법도 가능하다.
13-3-4. 스레드는 가능한 독립적으로 구현하라
독자적인 스레드로 가능하면 다른 프로세서에서 돌려도 괜찮도록 자료를 독립적인 단위로 분할하라
각 스레드는 다른 스레드와 자료를 공유하지 않고 클라이언트 요청 하나를 처리하도록 구현해라
모든 정보는 비공유 출처에서 가져오며 로컬 변수에 저장한다.
13-4. 라이브러리를 이해하라
언어가 제공하는 클래스를 검토하라
java가 제공하는 내장 라이브러리
concurrent
concurrent.atomic
concurrent.locks
를 익혀라.
13-4-1. 스레드 환경에 안전한 컬렉션
java.util.concurrent 패키지가 제공하는 클래스는 다중 스레드 환경에서 사용해도 안전하며, 성능도 좋다.
ConcurrentHashMap은 거의 모든 상황에서 HashMap보다 빠르다.
동시 읽기와 쓰기를 지원하며 자주 사용하는 복합 연산을 다중 스레드 상에서 안전하게 만든 메서드로 제공한다.
ReentrantLock : 한 메서드에서 잠그고 다른 메서드에서 푸는 락(lock)이다.
Semaphore : 전형적인 세마포이다. 개수가 존재하는 락이다.
CountDownLatch : 지정한 수만큼 이벤트가 발생하고 나서야 대기 중인 스레드를 모두 해제하는 락이다. 모든 스레드에게 동시에 공평하게 시작할 기화를 준다.
13-5. 실행 모델을 이해하라
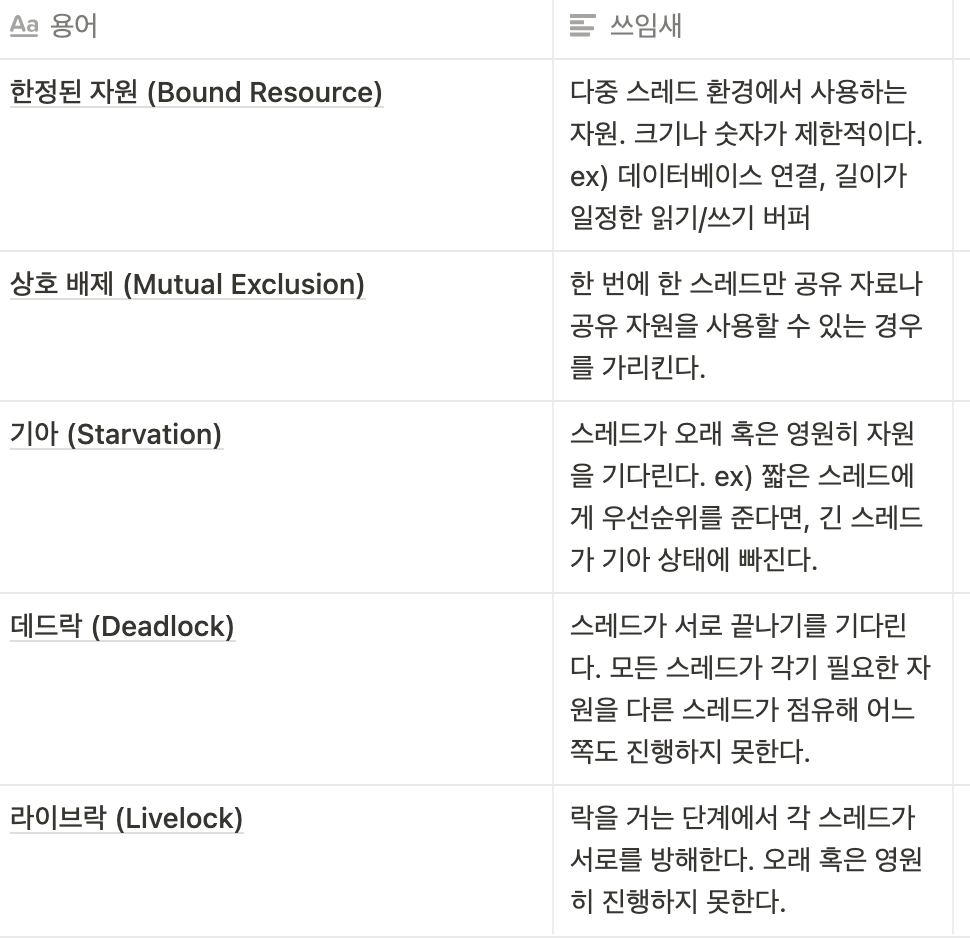
다중 스레드 애플리케이션에서 사용하는 실행 모델
생산자-소비자 (Producer-Consumer)
읽기-쓰기 (Readers-Writers)
식사하는 철학자들 (Dining Philosophers)
13-6. 동기화하는 메서드 사이에 존재하는 의존성을 이해하라
공유 객체 하나에는 메서드 하나만 사용하라.
동기화하는 메서드 사이에 의존성이 존재하면 동시성 코드에 찾아내기 어려운 버그가 생긴다.
자바는 메서드를 보호하는 synchronized를 지원한다.
공유 객체 하나에 여러 메서드가 필요하다면?
클라이언트에서 잠금클라이언트에서 첫 번째 메서드를 호출하기 전에 서버를 잠근다.
마지막 메서드를 호출할 때까지 잠금을 유지한다.
서버에서 잠금서버에 '서버를 잠그고 모든 메서드를 호출한 후 잠금을 해제하는 메서드'를 구현한다.
클라이언트는 이 메서드를 호출한다.
연결 서버잠금을 수행하는 중간 단계를 생성한다.
'서버에서 잠금'방식과 유사하지만 원래 서버는 변경하지 않는다.
13-7. 동기화 하는 부분을 최대한 작게 만들어라
자바에서 synchronized 키워드를 사용하면 락을 설정한다.
같은 락으로 감싼 모든 코드 영역은 한 번에 한 스레드만 실행이 가능하다.
락은 스레드를 지연시키고 부하를 가중시키므로, 여기저기 synchronized문을 남발하면 안 된다.
critical section은 반드시 보호해야 한다.
따라서 코드를 짤 때는 critical section의 수를 최대한 줄인다.
critical section 개수를 줄인다고 크기를 키우면 스레드 간에 경쟁이 늘어나고 프로그램 성능이 떨어진다.
13-8. 올바른 종료 코드는 구현하기 어렵다
종료 코드를 개발 초기부터 고민하고 동작하게끔 초기부터 구현하라.
생각보다 어려우므로 이미 나온 알고리즘을 검토하라.
13-9. 스레드 코드 테스트하기
문제를 노출하는 테스트 케이스를 작성하라.
프로그램 설정과 시스템 설정과 부하를 바꿔가며 자주 돌려라.
테스트가 실패하면 원일을 추적하라.
그냥 넘어가면 절대 안된다.
13-9-1. 말이 안되는 실패는 잠정적인 스레드 문제로 취급하라
시스템 실패를 '일회성'이라 치부하지 마라.
13-9-2. 다중 스레드를 고려하지 않는 순차 코드부터 제대로 돌게 만들자
스레드 환경 밖에서 생기는 버그와 스레드 환경에서 생기는 버그를 동시에 디버깅 하지 마라.
스레드 환경 밖에서 코드를 올바로 돌려라.
13-9-3. 다중 스레드를 쓰는 코드 부분은 다양한 환경에 쉽게 끼워넣을 수 있게 스레드 코드를 구현하라
다양한 설정에서 실행할 목적으로 구현하라.
13-9-4. 다중 스레드를 쓰는 코드 부분을 상황에 맞춰 조절할 수 있게 작성하라
적절한 스레드 개수를 조율하기 쉽게 코드를 구현한다.
프로그램이 돌아가는 도중에 스레드 개수를 변경하는 방법도 고려한다.
프로그램 처리율과 효율에 따라 스스로 스레드 개수를 조율하는 코드도 고민한다.
13-9-5. 프로세서 수보다 많은 스레드를 돌려보라
스와핑이 잦을수록 critical section을 빼먹은 코드나 데드락을 일으키는 코드를 찾기 쉬워진다.
13-9-6. 다른 플랫폼에서 돌려보라.
처음부터 그리고 자주 모든 목표 플랫폼에서 코드를 돌려라.
13-9-7. 코드에 보조코드를 넣어 돌려라. 강제로 실패를 일으키게 해보라
스레드 코드에서 오류를 찾기란 쉽지 않다.
간단한 테스트로는 버그가 드러나지 않는다.
이유는 수천 가지 경로 중 아주 소수만 실패하고, 실패하는 경로가 실행될 확률은 저조하기 때문이다.
드물게 발생하는 오류를 좀 더 자주 일으키려면, 보조 코드를 추가해 코드가 실행되는 순서를 바꿔준다.
ex) Object.wait(), Object.sleep(), Object.yield(), Object.priority()각 메서든는 스레드가 실행되
는 순서에 영향을 미친다.
따라서 버그가 드러날 가능성도 높아진다.
잘못된 코드라면 가능한 초반에 그리고 가능한 자주 실패하는 편이 좋다.
13-9-8. 직접 구현하기
드에다 직접 wait(), sleep(), yield(), priority()를 추가한다.
까다로운 코드를 테스트할 때 적합하다.
public synchronized String nextUrlOrNull() {
if(hasNext()) {
String url = urlGenerator.next();
Thread.yield(); // 테스트를 위해 추가
updateHasNext();
return url;
}
return n를 삽입하면 코드가 실행되는 경로가 바뀐다.
이전에 실패하지 않았던 코드가 실패할 가능성을 열어준다.
13-9-9. 자동화
흔들기(jiggle) 기법을 사용해 오류를 찾아낸다.
ThreadJigglePoing.jiggle()
호출은 무작위로 sleep이나 yield를 호출한다.
결말
동시성과 깨끗한 코드는 거리가 멀지만 이번 챕터를 통해 깨끗한 동시성이 무엇인지 어떻게 구현하는 것이 올바른 방법인지 알 수 있는 챕터.
14장 점진적인 개선
'Etc > Clean Code[ Robert C. Martin ]' 카테고리의 다른 글
| [Clean Code] 15장 JUnit 들여다보기 (0) | 2022.05.12 |
|---|---|
| [Clean Code] 14장 점진적인 개선 (0) | 2022.05.11 |
| [Clean Code] 12장 창발성 (0) | 2022.05.01 |
| [Clean Code] 11장 시스템 (0) | 2022.04.18 |
| [Clean Code] 10장 클래스 (0) | 2022.04.16 |